Rule engine
As indicated earlier the central component of VRMT consists of the Attribution that is carried out by the Rule Engine. It is the fundamental process during which
- source files are enriched with static information derived from source file attributes via Backend Rules. This adds new information primarily about the IT environment.
- enriched files are further transformed via Rule Manager to reflect detailed information about the vulnerability impact and the recipients within the organization who will ultimately decide about patching the weakness.
Though the scanning software might already provide some insights e.g. the severity of a weakness, this might not be sufficient for the IT Security Department to efficiently process it. Usually alerts need to be enriched with many company specific facts before they can be channeled to the right people. Such facts might be the affected IT environment: is it a development (DEV) or a production (PROD) system? Is it an internal file share for marketing material or a business-critical customer facing system? What team is responsible for what type of vulnerability?
In other words, the Rule Engine trains VRMT to differentiate priorities, understand system processes, and learn about the right recipients within organization.
The fundamental process of the Rule Engine is illustrated below:
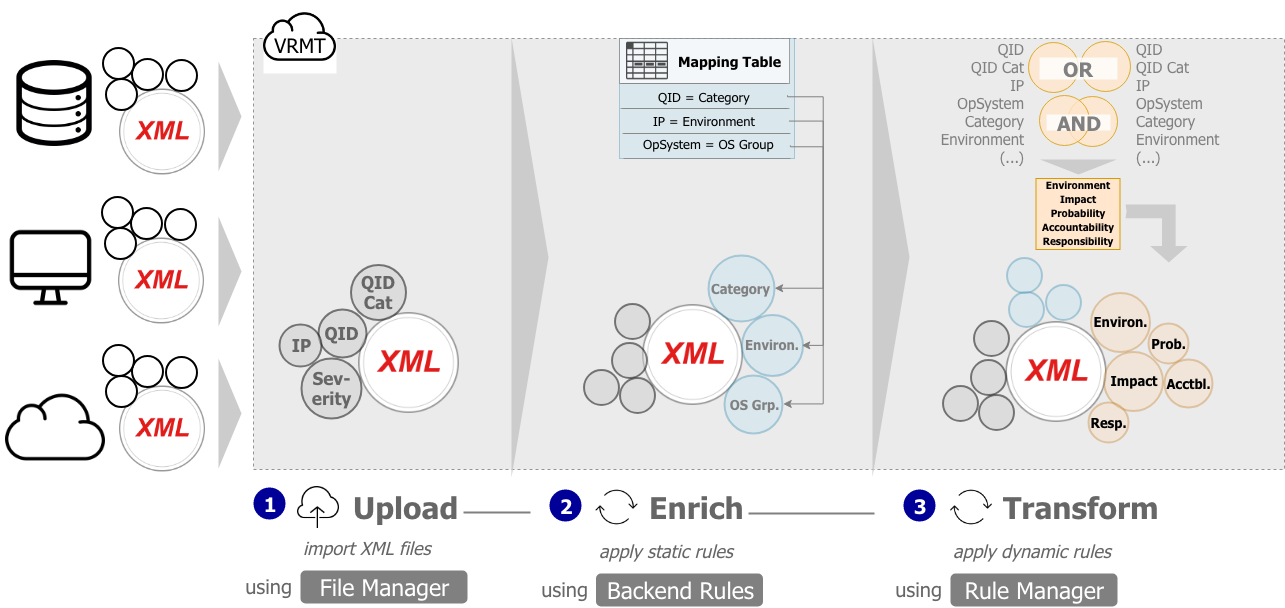
In a fist step XLM alert files are uploaded via the File Manager and mapped to a specific process using the Process Manager.
In a second step Backend Rules employ static rules to enrich alerts with fundamental information about the IT landscape.
During the third step dynamic rules transform existing attributes in such a way that they account for the fine-grained details of the security policy, consider exceptions and identify the correct recipients.
The entire Rule Engine of VRMT comprises the following components:
updated on: 5/9/2019 ⏐updated by: Wolfgang Stoettner ⏐ v1.0.1